

The Processing Pattern provides a simple mechanism to perform distributed grid computing operations with Coherence. It is structured as an extensible cluster-based processing engine, capable of accepting, dispatching and executing a variety of workloads, the types of which may be customized by developers.
Unlike the traditional hub-and-spoke / master-worker / broker-agent, the Processing Pattern avoids the classic "single-point-of-failure", "single-point-of-dispatch", "single-point-of-contention" problems by managing and distributing the core state across a Coherence Data Grid.
The Processing Pattern implementation is distributed in the jar file
called: coherence-processingpattern-11.0.0.jar.
However as the Processing Pattern has many dependencies, we **strongly recommend** that developers adopt and use tools like Apache Maven/Ivy/Gradle to transitively resolve the said dependencies, instead of attempting to do so manually.
To configure your Apache Maven-based application to use the Processing Pattern,
simply add the following declaration to your application pom.xml file
<dependencies> element.
<dependency>
<groupId>com.oracle.coherence.incubator</groupId>
<artifactId>coherence-processingpattern</artifactId>
<version>11.0.0</version>
</dependency>
The Processing Pattern has four key concepts; Processing Sessions, Submissions, Submission Outcomes and Dispatchers.
ProcessingSessions, also commonly called Sessions, provide the ability to
submit work for an implementation to process asynchronously. Additionally
ProcessingSessions provide mechanisms to disconnect and later reconnect
to previously submitted work, thus naturally permitting long running work
to be processed and monitored.
Submissions encapsulate the information representing the work to process.
Typically these are simply serialized objects. There's no contract
on how work is represented or interfaces to implement.
Upon submitting work, a ProcessingSession will return a SubmissionOutcome,
that of which may be used to track and manage the processing of the said work.
Once submitted, one or more configured Dispatchers are consulted to route
Submissions for appropriate processing. How processing actually occurs
is dependent on the type of Dispatcher and possibly the Submission.
Three dispatcher implementations are provided out-of-the-box:
A LoggingDispatcher that simply logs Submissions that have been submitted.
A LocalDispatcher that can execute Submissions that contain Java
Runnables and Callables.
A TaskDispatcher that can dispatch and execute Tasks, a more sophisticated
form of Callable.
While LocalDispatchers are very useful for processing standard Java asynchronous
processes, in most cases TaskDispatchers are the preferred type of dispatcher to
use when adopting the Processing Pattern.
The TaskDispatcher implementation leverages the following concepts:
A Task is a Submission that implements the Task interface. It is used
to provide information concerning a task, including properties for routing.
A specialized form of Task, called a ResumableTask is provided to permit
check-pointing (saving) of intermediate state, thus allowing said tasks to be
suspended and resumed as needed.
A TaskProcessor is an entity that actually executes Tasks.
Two types of TaskProcessor are provided. The first called
a Grid processor that of which is instantiated on all storage-enabled cluster
nodes. The second called a Single processor, that of which is instantiated
on a single storage-enabled cluster node with in a cluster.
A TaskDispatchPolicy governs how Tasks are allocated to TaskProcessors.
Three TaskDispatchPolicies are provided, including Round Robin,
Random and Attribute Matching.
The following section outlines the process by which ProcessingSessions may be
used to submit and manage Submissions.
Submitting work is main activity of a ProcessingSession. While there are several
overloaded variants of the ProcessingSession.submit method, the result of submitting
work is always a SubmissionOutcome instance, that of which is typically used to determine
the current SubmissionState together with current processing result(s) of a submission.
As the Processing Pattern requires that all Submissions be uniquely identifiable
(simply so that said Submissions may be tracked, managed and results of which may
retrieved at some point in the future) submitting work requires a decision to be
made concerning an appropriate Identifier to use. In general there are two
approaches to identifying work:
Explicitly specify and Identifier for each Submission or
Request that the ProcessingSession automatically generate one for you
(based on a UUID).
Regardless of the approach used, the Identifier for a Submission can always
be retrieved by calling SubmissionOutcome.getIdentifier() method.
Coherence Common defines a number of
Identifierimplementations, including those forString,Integer,LongandUUIDtypes, aptly namedStringBasedIdentifier,IntegerBasedIdentifier,LongBasedIdentifierandUUIDBasedIdentifier.
Auto Generated Submission Identifiers:
//submit the work (without an identifier specified it will create one)
SubmissionOutcome outcome = processingSession.submit(work, configuration);
//get the identifier created for the submission
Identifier id = outcome.getIdentifier();
Explicitly specified Submission Identifiers:
//create an identifier for the submission
Identifier id = new StringBasedIdentifier("my-work");
//submit the work
SubmissionOutcome outcome = processingSession.submit(id, work, configuration);
//get the identifier specified for the submission
Identifier idSubmission = outcome.getIdentifier();
//it will be the same as the one we specified when we submitted the work
assert id.equals(idSubmission);
Once a Submission has been submitted it is scheduled for acceptance (and
later processing) using an appropriate Dispatcher. Once accepted by a Dispatcher
a SubmissionOutcome is created and returned to the submitter, that of which may
request the status of any processing and/or retrieve results from processing.
After a Submission has been processed (either successfully or through to failure),
its internal representation together with its associated SubmissionOutcome
must be removed from the system to prevent excessive use of memory. The approach
used to control when and how this clean up occurs is defined by the configured
SubmissionRetentionPolicy.
When the SubmissionRetentionPolicy is set to RemoveOnFinalState, all internal
state related to a Submission is automatically removed when processing has finished
(either due to completion or failure). That is, clients are not required to
clean-up submissions once they are executed. This is the default behavior.
When the SubmissionRetentionPolicy is set to ExplicitRemove, all internal
state related to a Submission is held by the system until a corresponding call
to ProcessingSession.discardSubmission(Identifier) is made. That is, clients
must make every effort to clean-up the submissions explicitly themselves.
When a client ProcessingSession requires another client ProcessingSession
take over ownership of a Submission, the client must "release" the said
SubmissionOutcome using the ProcessingSession.releaseSubmission(SubmissionOutcome)
method, after which the later client may "acquire" ownership by calling
the ProcessingSession.acquireSubmission(...) method.
Releasing a Submission:
Identifier id = outcome.getIdentifier();
processingSession.releaseSubmission(outcome);
Acquiring a Submission:
//acquiring a submission
SubmissionOutcome outcome = processingSession.acquireSubmission(id, ...);
Identifiersused for representing Submissions are always serializable. Hence it's both legal and appropriate to serialize, store and transmit saidIdentifiersbetween applications and servers.
To cancel a submission you simply call the ProcessingSession.cancelSubmission(...)
method using the Identifier of the submission to cancel.
//get the submission identifier to cancel
Identifier id = outcome.getIdentifer();
//cancel the submission
processingSession.cancelSubmission(id);
Calling cancelSubmission will mark the Submission as being CANCELLED (if it
is not already in a final state). When this occurs, the SubmissionOutcome will
notified and any blocking calls (like SubmissionOutcome.get()) will return.
If the Submission has started processing, e.g. if a Runnable has started running,
the executing thread will be interrupted. If a Runnable has called wait, sleep
or join on the current thread, an InterruptedException will be thrown.
A Runnable / Callable / Task can check whether the Submission has been
cancelled by calling Thread.currentThread().interrupted() after which it may
subsequently abort processing/perform potential rollback/compensatory actions.
Here is an example of submitting and cancelling a Submission:
ProcessingSession session = new DefaultProcessingSession(StringBasedIdentifier.newInstance("SessionIdentifier"));
SubmissionOutcome outcome = session.submit(new DoNothingRunnable(15000),
new DefaultSubmissionConfiguration(null),
StringBasedIdentifier.newInstance("submissionId"),
SubmissionRetentionPolicy.ExplicitRemove,
null);
System.out.println("Wait a second before CANCELLING submission");
Thread.currentThread().sleep(1000);
session.cancelSubmission(outcome.getIdentifier());
outcome.get(); //Waits for a final state for the Submission.
A central concept of the Processing Pattern is the concept of Dispatchers. In
fact, for the Processing Pattern to operate at all, one or more Dispatchers must
be configured.
When a Submission is submitted to the Processing Pattern, it is first offered
to each of the configured Dispatchers, in the order in which they were defined
or registered.
Each Dispatcher interogates the Submissions they are offered to determine if
they are capable of handling the said Submissions. When a Dispatcher chooses
to accept a Submission, a SubmissionOutcome is returned to the calling client.
After this the accepting Dispatcher will attempt to find a way to process the
Submission. This may involved executing the Submission or in some cases, like
the TaskDispatcher locating a suitable TaskProcessor to process the Submission.
Should a Dispatcher choose to reject (not accept) a Submission, the said
Submission will be provided to the remaining Dispatchers in the configured
list of Dispatchers.
The following diagram illustrates the typical operational flow of an application using the Processing Pattern.
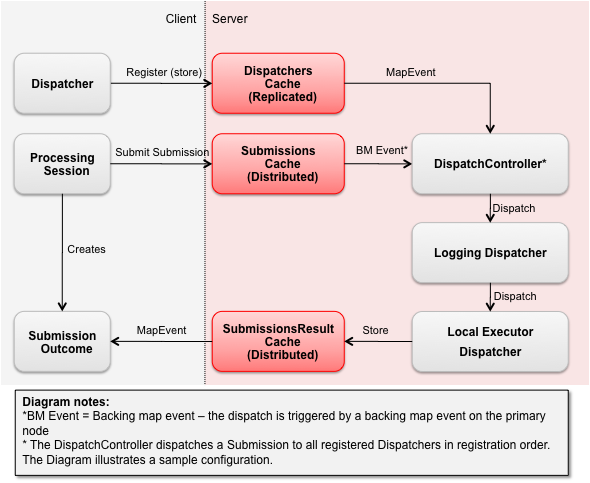
As mentioned previously, TaskDispatchers are special in that they themselves
don't execute Tasks. Instead they use the configured TaskDispatchPolicy to
determine a suitable TaskProcessor, that of which will actually execute submitted
Tasks.
Typically a TaskDispatchPolicy simply compares the attributes supplied as part
of a SubmissionConfiguration with those that are defined by each TaskProcessor.
This activity is typically called Task Mediation.
The following diagram illustrates the typical operational flow of an application
using Tasks with the Processing Pattern.
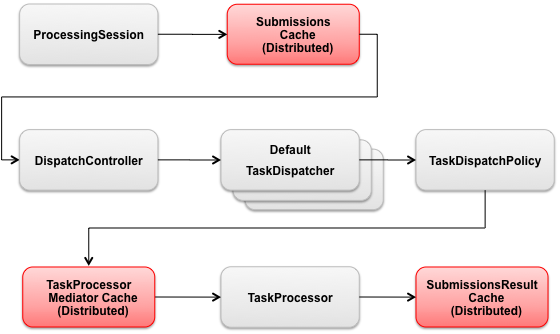
The following demonstrates a simple example of the Processing Pattern.
package com.oracle.coherence.examples.incubator.processing.task;
import java.util.concurrent.ExecutionException;
import com.oracle.coherence.common.identifiers.StringBasedIdentifier;
import com.oracle.coherence.patterns.processing.ProcessingSession;
import com.oracle.coherence.patterns.processing.ProcessingSessionFactory;
import com.oracle.coherence.patterns.processing.SubmissionOutcome;
import com.oracle.coherence.patterns.processing.internal.DefaultSubmissionConfiguration;
import com.tangosol.net.CacheFactory;
public class PiCalculationSample
{
public void executeTask() throws Exception
{
System.out.println("Testing PI calculation");
ProcessingSession session = new DefaultProcessingSession(StringBasedIdentifier
.newInstance("PICalculationSample " + DateFormat.getDateTimeInstance().format(System.currentTimeMillis())));
SubmissionOutcome pioutcome = session.submit(new CalculatePITask(100000), new DefaultSubmissionConfiguration());
System.out.println("PI (100000) iterations is :"+ pioutcome.get().toString());
factory.shutdown();
CacheFactory.shutdown();
}
public static void main(String[] args)
{
PiCalculationSample sample = new PiCalculationSample();
try
{
sample.executeTask();
}
catch (Exception e)
{
e.printStackTrace();
}
}
}